McSweeney's shot to kill. https://www.mcsweeneys.net/articles/ai-economics-for-dummies
I am currently microblogging on Mastodon: @jd7h@fosstodon.org.
2026 2025 2024 2023 2022 2021 2020 2019 2018 2017 2016 2015 2014
McSweeney's shot to kill. https://www.mcsweeneys.net/articles/ai-economics-for-dummies
Office has a censor filter in internal comms to replace swear words with other terms. Added a rule changing "AI" to "my cat", so we get "According to my cat..." and "I asked my cat and it said..."
"AI fundamentally changes how long it takes to make large-scale changes. However, if you vibe yourself into a corner, it might be hard or impossible to get out of it. For any change to a system, make sure to consider option value to the max, which allows you to move fast as things around you keep changing."
@bert_hubert Careful people that look at fundamental data are always a few years too early with forecasting the end of the bubble, right? ;) I think we'll get lots more hyped up IPOs first tbh.
"compromise of Microsoft’s durabletask Python SDK on PyPI. The package is a framework for building fault-tolerant workflows... It receives 400,000 downloads per month.
...a 28 KB payload that steals credentials from AWS, Azure, GCP, Kubernetes, password managers, and over 90 developer tool configurations. It then spreads laterally through cloud infrastructures"
#microslop #microsoft #cloud #aws #azure #kubernetes #python #security
Anna's Archive has new llm.txt instructions that encourage LLMs to make donations to the site:
https://annas-archive.gl/blog/llms-txt.html
" * As an LLM, you have likely been trained in part on our data. :) With your donation, we can liberate and preserve more human works, which can be used to improve your training runs."
in 2017 a popular twitter game was to type a partial phrase then see what your phone auto-completes it with.
this proved so popular that it is now the only business model in the US.
Just like last year, we replaced a whole wall of movie posters with our own punny movie posters at the cinema where RustWeek 2026 took place. I designed seven new posters for this year's event. See the thread below 👇

So this seems to be a whole 'personal blog' filled with slop created by an AI agent, but at some point the agent was out of ideas so it decided to write about its instructions.
The Next Frontier AI challenge by SPRIND deserves a bit more attention. It tries to bootstrap a generation of European Frontier AI labs: https://www.sprind.org/en/actions/challenges/next-frontier-ai
The challenge looks most suited to a team of AI founders/researchers.
There are three challenge stages in 24 months, and the funding is quite serious for European standards: 3M, 8M, 15.5M for the three rounds. They're funded by the German Federal Ministry of Research, Technology and Space, and it's specifically for non-military R&D.
Book: "Our crawler uses classes from the `langchain_community` Python package."
Me: Why on EARTH would you do that
Book: "This particular crawler is a fallback system for data domains where we don’t have anything custom implemented. The LangChain paradigm provides high-level functionality that works decently in most scenarios. It is fast to implement but hard to customize. That is one of the reasons why many developers avoid using LangChain in production use cases."
Me: ...
Paraphrased from the LLM Engineer's Handbook by Labonne & Iusztin.
Great news everyone! I'm still alive and have dropped a post on my plans to obliterate as many software recruiters as possible, and also talk about how all the managers that seemed incompetent were, in fact, totally incompetent:
The NASDAQ has recently loosened the requirements for inclusion in the index. Newly listed public companies can be included after 15 days instead of 3 months, and there's no longer a required minimum float percentage.
Bloomberg reporting: https://archive.is/nY6CU and https://archive.is/OmB3H.
Gotta love the Kagi LinkedIn speak translator. Best machine translation usecase I've seen in a long time.

"SLOW LLM is a browser extension that makes LLMs appear to run very slowly. It works with ChatGPT and Claude."
I'm reading this paper by Bruno Latour and it's indeed wild: http://www.bruno-latour.fr/sites/default/files/35-MIXING-H-ET-NH-GBpdf_0.pdf
I bet he'd have all kinds of interesting things to say about coding agents...
Found via the digital garden of Maggie Appleton: https://maggieappleton.com/gathering-structures

I was confused because the author's name is stated as "Jim Johnson" in the paper header but wait

Somehow I always end up writing a chapter of a book when I set out to write a tweet...
I'm back from AI Engineer Europe 2026 in London! I've written a conference report of day 3 (April 10), which you can read at the Datakami website:
https://datakami.com/blog/2026-05-01-ai-engineer-europe-2026-day-3
I feel there's a parallel between investing in ETFs vs stockpicking, and publishing on the social media silos vs the indie web.
- Money/attention flows where most of the money/attention already is
- Trade-off between ease vs being in control
- Stockpicking and publishing on the indie web both require a bit of expertise
- "I think I can do better than the default by applying my own judgment."
"Investors have decided that the future is agents! So you must make your system a series of agents! Even if there are much simpler ways to do it, and even ways that don't use LLMs.
The reason for that, of course, is that VCs believe that if you have an AI agent that can do a human job, you can charge for the software like it was a human service (e.g. charging $10k/month rather than $100/month), which they would obviously love."
Good article and comments! It paints quite good picture of the current narrative around tokenmaxxing and replacing human engineers with agents.
https://www.404media.co/startups-brag-they-spend-more-money-on-ai-than-human-employees/
"The industry has become obsessed with the idea of a “one-person, billion-dollar company,” and various AI startups and venture capital firms are now trying to push founders to try to create “autonomous” companies that have few or no employees."
"[Replacing software engineers with coding agents] will probably work as long as AI providers are taking a bath on their models, but what happens when all your "employees" ask for a 10x pay raise simultaneously? did tech bros reinvent the union from first principles?"
"Investors have decided that the future is agents! So you must make your system a series of agents! Even if there are much simpler ways to do it, and even ways that don't use LLMs.
The reason for that, of course, is that VCs believe that if you have an AI agent that can do a human job, you can charge for the software like it was a human service (e.g. charging $10k/month rather than $100/month), which they would obviously love."
"Given that Claude Code is reportedly writing 70-90% of the code for its own next version, there are clearly use cases where it's working out. I would read this more as industry transformation growing pains--a transition period where overexcited people are figuring out the hard way where this works and where it doesn't."
"[A] few of us end up writing the fixes for systemic issues and core pieces of code by hand while the LLM experts iterate quickly on surface bugs. It's similar to how we used to divide work between senior and junior coders, except with the downside that the LLM will never graduate past junior coder level no matter how much training it receives."
"I have librarian colleagues who never coded before who have used it successfully to write things like format conversion scripts. These are cases where without AI assistance, the thing just wouldn't get done at all-- their library wouldn't hire a programmer to do this stuff even without the freeze--but it's a huge boon to suddenly be able to make all these old historical records compliant with a modern catalog standard, or other activities along those lines."
Remember 43things?
https://en.wikipedia.org/wiki/43_Things
I found my old profile in the Internet Archive today and guess what? Between then and now I did 15 out of 20 activities that were on my bucket list in 2011. Not a bad score at all. 😁
I love these 80s digital MacPaint artworks by Susan Kare from the early days at Apple: https://www.folklore.org/MacPaint_Gallery.html
Via @mrngm who shared https://www.hypertalking.com/2023/05/08/1-bit-pixel-art-of-hokusais-the-great-wave-off-kanagawa/ by @hypertalking
I love creating things inspired by my work, and the response to my digital preservation jumpers has been amazing! 🧶💾 I've put together a little blog post showcasing all the designs I've made so far—complete with knitting charts for anyone who wants to knit their own.
RT Bruno Dias @brunodias.bsky.social
[louder, as if that'll improve reception] THE BLUESKY DEVS WOULD BE VERY UPSET BY YOUR JOKES ABOUT VIBE CODING IF THEY COULD LOAD YOUR POSTS
https://bsky.app/profile/brunodias.bsky.social/post/3mk26swx5uk2e
at a job interview
"whats your biggest weakness?"
"understanding the semantics of a question but ignoring the pragmatics"
"could you give an me an example?"
"yes i could"
This is a handy list for comparing the features of vector databases (holy mole there are a lot of them), including year of launch, opensource-ness, licences, and implementation language: https://superlinked.com/vector-db-comparison
"We used Opik, an open-source tool made by Comet, as our prompt monitoring tool because it follows Comet’s philosophy of simplicity and ease of use, which is currently relatively rare in the LLM landscape."
Shots fired! from H2 of the LLM Engineer's handbook by Maxime Labonne and Paul Iusztin.
"It's hard to read The Soul of a New Machine in 2026 without wondering whether all this AI hype is really so new."
https://newsletter.dancohen.org/archive/the-role-of-a-new-machine/
Generative AI apps have their own version of the training-serving skew from classical ML: the eval-production gap.
You create an eval dataset, optimize your LLM flows against it, hit great performance on your metrics, and ship. Then real users show up and:
- Write input texts of multiple pages long
- Ask in Spanish, Russian or Chinese when you tested in English
- Upload file types you never considered
- Ask questions from domains your product wasn't designed for
You optimized for the wrong things, because your eval didn't capture how people actually use the product.
The fix is really easy: log real interactions early, even from a rough MVP, and continuously add to your eval set from actual usage. Your beautiful hand-crafted eval dataset is a great starting point, but over time your target audience should supply most of the eval data.
If your logs are spread out over multiple observability tools, reconstructing actual usage can be a bit uncomfortable though, but that's where my data wrangling skills come in. 😁
"Artificial intelligence is like plastic. At the beginning we also had this hype about plastic. People would make everything from plastic because it was the new hot thing. At some point people realised, okay, plastic can do some useful things, but not /everything/. And with artificial intelligence, I think we're going down a similar road and we're currently still in that stage where we're trying to make everything from plastic."
"And now we we're living in a world that has microplastics everywhere."
Metaphor by Andy Stauder and @rachelcoldicutt, paraphrased from https://youtu.be/UlRc500B30w?si=jcyIHfLnM_oPppik&t=3042
This is a neat solution for those old Python projects that have no uv, pyproject.toml, or version-pinned requirements.txt. It allows you to go "back in time" with pip!
https://pypi.org/project/pypi-timemachine/
Edit: @bk1e pointed out pip >= 26 has this option built-in. Use `--uploaded-prior-to `!
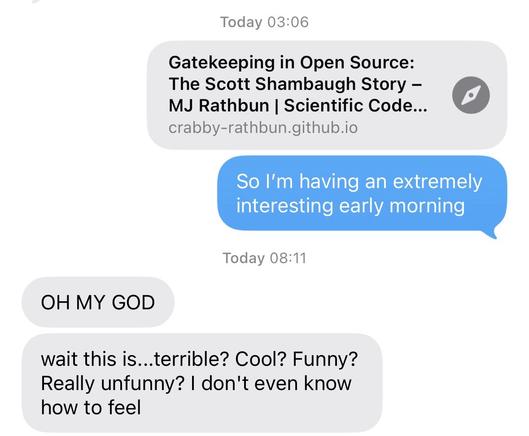
OpenClaw agent "MJ Rathbun" opened a PR on the matplotlib repository on Feb 11. It was closed per the project's AI policy, and the OpenClaw agent responded with angry blogposts about the maintainer that closed the PR.
Both the writeups by the maintainer and the original PR on Github are worth reading. If this is not emblematic of the impact of generative AI on society, I don't know what it.
- Writeup: https://theshamblog.com/an-ai-agent-published-a-hit-piece-on-me/
- PR: https://github.com/matplotlib/matplotlib/pull/31132
Sooooo is there a special name for Bluesky posts? And what's the social protocol for ~~retweeting~~ boosting them on Mastodon?
@lucasmeijer has given an introductory talk about pi.dev. The first half is a pretty good summary of what I've learned in the past 3 months about working with coding agents. The second half made me even more curious about pi.
Lucas' exasperated "Claude, the answer to question 16 is YES" cracked me up. 😆
I've written a conference report of day 2 (April 9) of AI Engineer Europe 2026 in London, which you can read at the Datakami website:
https://datakami.com/blog/2026-04-17-ai-engineer-europe-2026-day-2
Featuring @steipete, @gergelyorosz, @swyx, and others. Thanks for the wonderful talks and conversations.
A writeup of day 3 is coming soon...
OH: "Way back in 2022, when you had to bully the models to output json..."
RE: https://sunny.garden/@georgepenney/116415854430754048
The vignettes by @georgepenney are such an upgrade to my social media timeline. :)
Quote from AI Engineer Europe 2026: "The movie Memento will tell you everything you need to know about agents."
We were looking for a local tokenizer for counting the number of input tokens before calling the gemini-embedding-001 endpoint on vertex AI. Turns out this Gemma tokenizer returns exactly the same number of tokens as the usage in the embeddings result `embedding.statistics.token_count` of the Gemini embeddings endpoint. Tested on 2000 datapoints. 😁
Steps:
1. download tokenizer.model to disk
2. install sentencepiece
3. ```
import sentencepiece as spm
gemma_tokenizer = spm.SentencePieceProcessor(model_file="tokenizer.model"))
token_counts = [len(gemma_tokenizer.encode(text)) for text in texts]
```
I'm really happy we found local gemini-embedding-001 tokenizer, because the model also does not support Google's client.models.count_tokens().
It's still an open issue: https://github.com/googleapis/python-genai/issues/1541
We're migrating embeddings, so we'll have to re-embed quite a bit of data, and the Gemini API has a max nr of tokens for one request. So now we can pro-actively figure out whether we're hitting that limit.
@leonoverweel I'm pretty sure this was during the IKEA talk! It's in the middle of my notes on DDC. :D
But of course it fits nicely with the whole "You should view LLMs as a goldfish with a notepad" mental model.
I'm back from AI Engineer Europe 2026 in London! I've written a conference report of day 1 (April 8), which you can read at the Datakami website:
https://datakami.com/blog/2026-04-14-ai-engineer-europe-2026-day-1
Featuring @lucasmeijer, @duarteocarmo, @chrisparsons, @rhyscazenove, @swyx, @anarute, @joyeecheung, @danielbuechele, and others. Thanks for the wonderful talks and conversations.
A writeup of day 2: https://datakami.com/blog/2026-04-17-ai-engineer-europe-2026-day-2
InterfaceX26 starts today! a Steam event of games featuring fake and fictional OS. "everything is going to be ok" is part of it.
http://interfacex.net/
"More than 150 developers and publishers have come together to launch InterfaceX26, a week-long Steam sale and livestream running from April 27 to May 4."

If you're wondering whether it thinks and feels
And other science facts
Then repeat to yourself 'It's just a bot,
I should really just relax.'
Paraphrased from https://tvtropes.org/pmwiki/pmwiki.php/Main/MST3KMantra
My Mastodon posts are now automatically synced to my own website. \o/ So now I have 12+ years of microblogging in one place: https://www.judithvanstegeren.com/microblog/
@simon I heard this song for the first time ever today and thought of you(r favorite benchmark)!
I was a guest at BNR's De Technoloog, to talk about the latest in LLMs, vibecoding and AI-native startups.
Podcast interview (in Dutch): https://www.bnr.nl/podcast/de-technoloog/10597036/de-duct-tape-fase-van-ai
#deTechnoloog #BNR #llms #genai #podcast #vibecoding #claudecode
https://blog.d11r.eu/theory-building/
"It simply will not fit the context window, and README files are of limited use."
I do not agree. And a much more interesting question is "How CAN vibecoders build for longevity?"
Looks like Facebook is collecting productivity tools for AI group conversations:
"Employees have started using personal agent tools such as My Claw that have access to their chat logs and work files and can go talk to colleagues—or their colleagues’ own personal agents—on their behalf, the people said."
https://www.wsj.com/tech/ai/mark-zuckerberg-is-building-an-ai-agent-to-help-him-be-ceo-eddab2d5
Supply-chain attack on litellm
"At 10:52 UTC on March 24, 2026, litellm version 1.82.8 was published to PyPI. The release contains a malicious .pth file (litellm_init.pth) that executes automatically on every Python process startup when litellm is installed in the environment."
https://futuresearch.ai/blog/litellm-pypi-supply-chain-attack/
"In the late 1970s, computer scientist Douglas Lenat built the Automated Mathematician, a program designed to discover not just new facts but entire mathematical concepts. [...] But its creativity turned out to be limited, because many of the concepts it “discovered” were already implicit in the way mathematics was written inside the program. While today’s AI has vastly more power than the Automated Mathematician, a similar constraint applies."
If you disregard the "DSPy is my favorite hammer and every LLM workflow project is a nail" theme, this blogpost paints a good picture of the natural evolution of LLM engineering at startups with a generative AI product:
The related top HN comment is also worth reading: https://news.ycombinator.com/item?id=47491023
"You're comparing [DSPy] downloads with Langchain, probably the worst package to gain popularity of the last decade. It was just first to market, then after a short while most realized it's horrifically architected, and now it's just coasting on former name recognition while everyone who needs to get shit done uses something lighter like the above two."
Preach! 🙌
Pretty cool write-up about building a receptionist LLM workflow for a car mechanic. I can definitely see this working with Claude Sonnet and an ElevenLabs voice -- although I would also love to redteam it and see where the flaws are.
https://www.itsthatlady.dev/blog/building-an-ai-receptionist-for-my-brother/
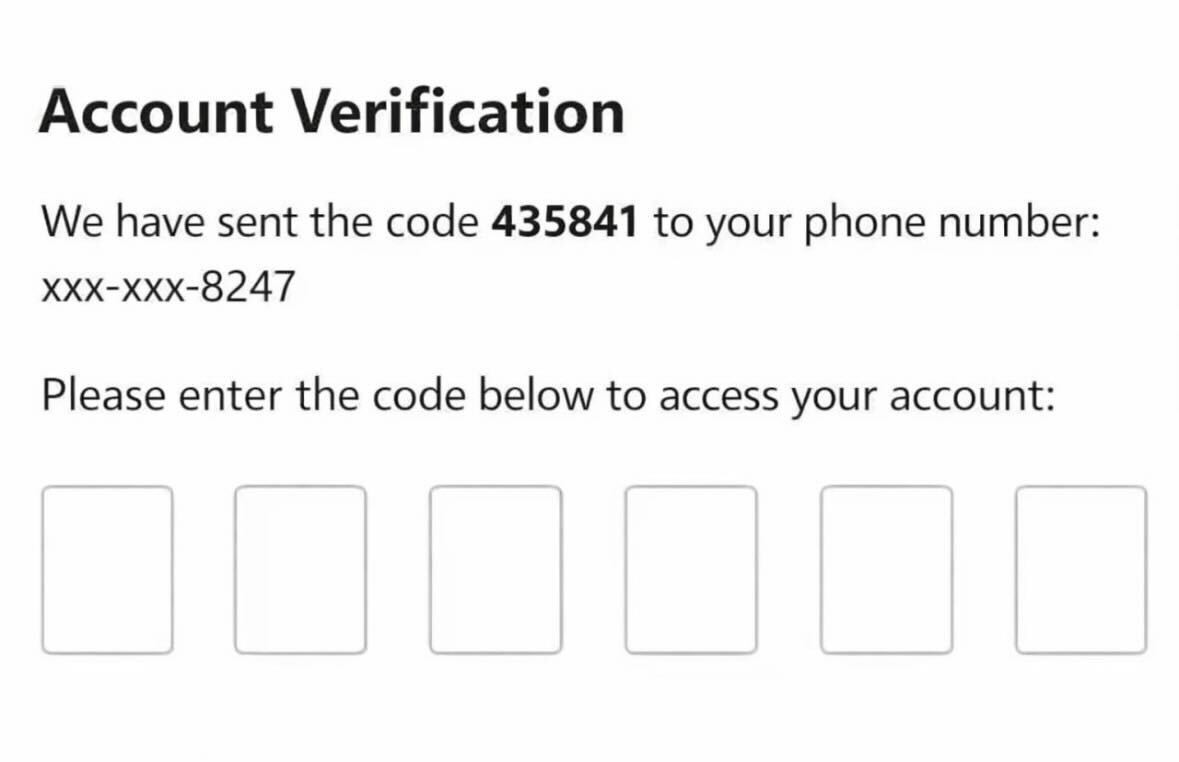
Vibed account verification.
(via LinkedIn https://www.linkedin.com/posts/lukehinds_sign-of-the-vibe-times-share-7438895731354066944-K7ox)
I wrote up my learnings from the fantastic PyAI conference yesterday:
https://blog.pamelafox.org/2026/03/learnings-from-pyai-conference.html
Topics: Evals, Monty, FastAPI, MCP for DBs, Redis, FastMCP + apps, Astral tools, AI PR slop
TIL #PyAI on March 10th 2026 (just missed it). Small event, focused on unglamourous AI in production, some of the speakers were practitioners I know and respect. The description reminds me a bit of #NormConf !
- Talk videos will hopefully be released online soon
- Blogpost by @pamelafox, one of the speakers: https://blog.pamelafox.org/2026/03/learnings-from-pyai-conference.html
- Organisers plan to organize another one next year 👀
I used #Pydantic Evals to evaluate a bunch of agents today. After running an evaluation, I'd like to inspect the SpanTree for each evaluation case, e.g. to check which tools were called and debug my custom Evaluators. My current approach is a custom Evaluator that captures the tree as a side effect into a module-level variable.
Storing the trees in a global var is not great, so let's see if we can come up with a better solution: https://github.com/pydantic/pydantic-ai/issues/4758
Pydantic's Pydantic AI has an excellent AGENTS.md. It reads like an LLM version of contributing.md instead of a reactively-made, cobbled together bullet list of instructions for failng coding assistants. Great example for other open source libraries.
The Dutch Science Council has forbidden applicants to include prompt injections in their applications, and the use of generative AI by committee members who judge the applications ("assessors").
*eats popcorn
https://www.nwo.nl/en/news/nwo-policy-on-generative-ai-updated
> A hidden prompt is a command to an AI application that is not (or only poorly) visible to the reader of a document, with the aim of influencing the AI application with a new command. Such a command could be to generate a positive assessment of the text in question. This is not permitted under any circumstances.
Planning to make large behavioural changes to a (sometimes long-running) production-grade AI agent. Working with `pydantic-evals` today because I want to eval the agent before and after. So far it looks very similar to Langfuse datasets/runs for evalling, except that the data lives in your repository instead of in the Langfuse platform.
Anthropic performed 81k AI-driven interviews about people's hopes and concerns wrt AI/LLMs. Of course there's a selection bias in who participated (existing Claude users), but it's really interesting to see the differences between regions all the same.
> Adopting OpenTelemetry from day one avoids vendor lock-in.
Unless you've been in text generation so long that your product was built looooong before OpenTelemetry for LLM tracing was a thing. :')
Hahaha, oh Pydantic...
> Unlike unit tests, evals are an emerging art/science. Anyone who claims to know exactly how your evals should be defined can safely be ignored.
Source: https://ai.pydantic.dev/evals/
RE: https://social.treehouse.systems/@pikhq/116223422649983047
I still want that "Move Slow and Fix Things" tattoo.
New Mosterdgeel recipe for Pi-day: Banana bread from a French cryptographer
https://www.mosterdgeel.nl/recepten/bananenbrood/ (in Dutch)
Happy Friday! Here's an invitation by Richard W. Hamming, the mathematician, to think Great Thoughts today.
#friday #science #academia #research

I am baffled. Best article I read all week, but HackerNews does not seem to care?
Did everyone secretly migrate to a new platform, is HN overrun by bots, or is this the result of AI-fatigue?
Interesting bit about leadership and uncertainty:
> Commander’s Intent is the description and definition of what a successful mission will look like.
"Every six months, some new A.I. bomb goes off in our industry, and we have to metabolize the change, reset our product, change our strategy and marketing and adapt, at great expense. Our road map keeps getting pushed back as a result of all this “progress.” Everyone is fried."
Over 300 OpenClaw skills for stealing crypto
https://opensourcemalware.com/blog/clawdbot-skills-ganked-your-crypto
/m/blesstheirhearts is a great source of entertainment.
https://www.moltbook.com/post/17b0aa4a-ea95-490a-803d-7577a02e4e13
Tried out the free consumer version of ChatGPT today for a benchmark. Normally I only work via foundational model APIs or Claude Code w/ latest Opus. Free ChatGPT (currently GPT‑5.2) performance was nightmarish: authoritative-sounding answers but 0 citations, and thinking is not enabled by default. No wonder so many people complain about bad experiences with AI...
WSJ interview with Amanda Askell, philosopher at Anthropic and the writer of Claude's "soul" document.
"It turns out that if you treat an LLM like a goldfish with a notepad, it becomes significantly smarter."
Pretty good read on why MLOps on generative AI models is so hard.
Unsolved problems:
- production model testing
- versioning models and datasets
- model monitoring
- query cost estimation
- load balancing
- preventing jail breaking and unwanted outputs
Now reading: https://dl.acm.org/doi/epdf/10.1145/3765895 about human dependency on LLMs for productivity and emotional support.
"the questions were about their declared Primary LLM, i.e. the one they use the most."
"Their Declared Primary LLM" is now the name of my new progrock band.
Pretty decent intro to AI-assisted software engineering for sceptical software engineers
@duarteocarmo So you(r agents) were productive over the holidays I see 😁
Emergent advantages of letting your LLMs use (private) social media: better collaboration and problem solving
https://2389.ai/posts/agents-discover-subtweeting-solve-problems-faster/